Browser¶
- 浏览器崩溃的边缘案例
- 内容更新和页面变化联系起来
- 死锁「寄!」
- JS 编写完到发布到线上的过程。
Storage¶
cookie sessionStorage localStorage 区别¶
浏览器缓存控制详解(cookie、session、localStorage、Cache-Control等) - 掘金
共同点:都是保存在浏览器端、且同源的
区别:
- cookie数据始终在同源的http请求中携带(即使不需要),即cookie在浏览器和服务器间来回传递,而sessionStorage和localStorage不会自动把数据发送给服务器,仅在本地保存。cookie数据还有路径(path)的概念,可以限制cookie只属于某个路径下
- 存储大小限制也不同,cookie数据不能超过4K,同时因为每次http请求都会携带cookie、所以cookie只适合保存很小的数据,如会话标识。sessionStorage和localStorage虽然也有存储大小的限制,但比cookie大得多,可以达到5M或更大
- 数据有效期不同,sessionStorage:仅在当前浏览器窗口关闭之前有效;localStorage:始终有效,窗口或浏览器关闭也一直保存,因此用作持久数据;cookie:只在设置的cookie过期时间之前有效,即使窗口关闭或浏览器关闭
- 作用域不同,sessionStorage不在不同的浏览器窗口中共享,即使是同一个页面;localstorage在所有同源窗口中都是共享的;cookie也是在所有同源窗口中都是共享的
- web Storage支持事件通知机制,可以将数据更新的通知发送给监听者
- web Storage的api接口使用更方便
得分点 数据存储位置、生命周期、存储大小、写入方式、数据共享、发送请求时是否携带、应用场景
Cookie、SessionStorage、 LocalStorage都是浏览器的本地存储。
- 它们的共同点:都是存储在浏览器本地的
- 它们的区别:cookie是由服务器端写入的,而SessionStorage、 LocalStorage都是由前端写入的,cookie的生命周期是由服务器端在写入的时候就设置好的,LocalStorage是写入就一直存在,除非手动清除,SessionStorage是页面关闭的时候就会自动清除。
- cookie的存储空间比较小大概4KB,SessionStorage、 LocalStorage存储空间比较大,大概5M。
- Cookie、SessionStorage、 LocalStorage数据共享都遵循同源原则,SessionStorage还限制必须是同一个页面。
- 在前端给后端发送请求的时候会自动携带Cookie中的数据,但是SessionStorage、 LocalStorage不会
由于它们的以上区别,所以它们的应用场景也不同,Cookie一般用于存储登录验证信息SessionID或者token ,LocalStorage常用于存储不易变动的数据,减轻服务器的压力,SessionStorage可以用来检测用户是否是刷新进入页面,如音乐播放器恢复播放进度条的功能。
chat
cookie、sessionStorage、localStorage 都是用于在浏览器端存储数据的技术,它们之间有以下区别:
- 存储数据的生命周期不同:
cookie的生命周期是由设置的过期时间决定的,如果没有设置过期时间,那么 cookie 的生命周期就是当前浏览器进程的生命周期。sessionStorage的生命周期只存在于当前的会话中,当关闭当前浏览器标签页或窗口时,存储的数据也会被清除。localStorage的生命周期则更长久,除非用户主动删除或者清除浏览器缓存,否则存储的数据会一直存在。
- 存储数据的大小限制不同:
cookie的大小限制为 4KB 左右。sessionStorage和localStorage的大小限制一般为 5MB 左右。
- 存储数据的作用域不同:
cookie是由服务器生成的,可以设置其在整个域名下都有效,也可以设置其只在某个路径下有效。sessionStorage和localStorage都是由浏览器生成的,它们的作用域都是在当前浏览器窗口下的所有页面。
- 存储数据的安全性不同:
cookie存储的数据可以在浏览器端被轻易地查看和修改,因此不适合存储敏感信息。sessionStorage和localStorage存储的数据则相对安全一些,可以用于存储一些敏感信息。
综上所述,cookie、sessionStorage、localStorage 适用的场景不同,需要根据实际情况进行选择。如果需要存储较大量的数据,并且需要在不同的浏览器窗口之间共享数据,那么可以使用 localStorage ;如果需要存储临时数据,并且不需要在不同的浏览器窗口之间共享数据,那么可以使用 sessionStorage ;如果需要存储一些临时数据,并且需要与服务器交互,那么可以使用 cookie。
会过期的localStorage¶
定时删除localstorage¶
localStorage 能跨域吗¶
不能
解决方案:
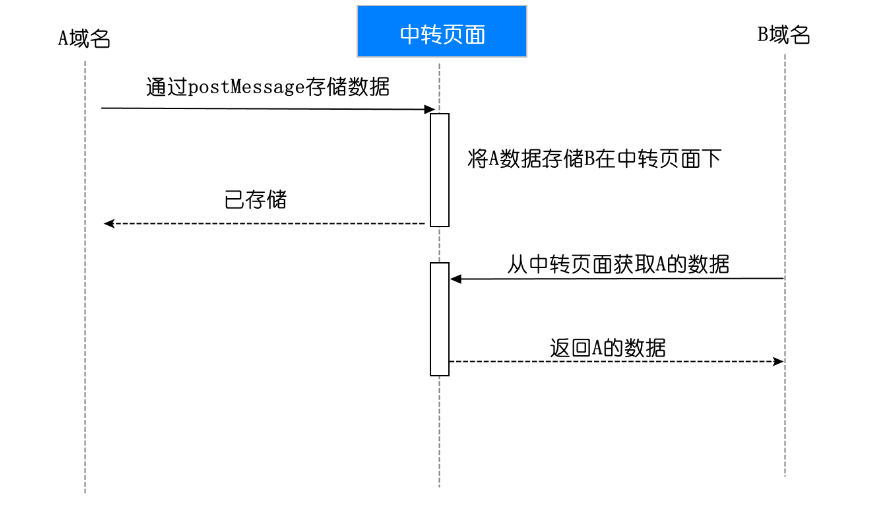
- 通过postMessage来实现跨源通信
- 可以实现一个公共的iframe部署在某个域名中,作为共享域
- 将需要实现localStorage跨域通信的页面嵌入这个iframe
- 接入对应的SDK操作共享域,从而实现localStorage的跨域存储
memory cache 如何开启¶
localstorage 的限制¶
- 浏览器的大小不统一,并且在IE8以上的IE版本才支持localStorage这个属性
- 目前所有的浏览器中都会把localStorage的值类型限定为string类型,这个在对我们日常比较常见的JSON对象类型需要一些转换
- localStorage在浏览器的隐私模式下面是不可读取的
- localStorage本质上是对字符串的读取,如果存储内容多的话会消耗内存空间,会导致页面变卡
- localStorage不能被爬虫抓取到
localStorage 扩容¶
-
iframe + postMessage
-
Index DB
cookie¶
cookie 是什么?¶
- cookie 是存储于访问者计算机中的变量。每当一台计算机通过浏览器来访问某个页面时,那么就可以通过 JavaScript 来创建和读取 cookie。
- 实际上 cookie 是存于用户硬盘的一个文件,这个文件通常对应于一个域名,当浏览器再次访问这个域名时,便使这个cookie可用。因此,cookie可以跨越一个域名下的多个网页,但不能跨越多个域名使用。
- 不同浏览器对 cookie 的实现也不一样。即保存在一个浏览器中的 cookie 到另外一个浏览器是 不能获取的。
- PS:cookie 和 session 都能保存计算机中的变量,但是 session 是运行在服务器端的,而客户端我们只能通过 cookie 来读取和创建变量
cookie 能做什么?¶
- 用户在第一次登录某个网站时,要输入用户名密码,如果觉得很麻烦,下次登录时不想输入了,那么就在第一次登录时将登录信息存放在 cookie 中。下次登录时我们就可以直接获取 cookie 中的用户名密码来进行登录。
- PS:虽然 浏览器将信息保存在 cookie 中是加密了,但是可能还是会造成不安全的信息泄露
- 类似于购物车性质的功能,第一次用户将某些商品放入购物车了,但是临时有事,将电脑关闭了,下次再次进入此网站,我们可以通过读取 cookie 中的信息,恢复购物车中的物品。
- PS:实际操作中,这种方法很少用了,基本上都是将这些信息存储在数据库中。然后通过查询数据库的信息来恢复购物车里的物品
- 页面之间的传值。在实际开发中,我们往往会通过一个页面跳转到另外一个页面。后端服务器我们可以通过数据库,session 等来传递页面所需要的值。但是在浏览器端,我们可以将数据保存在 cookie 中,然后在另外页面再去获取 cookie 中的数据。
- PS:这里要注意 cookie 的时效性,不然会造成获取 cookie 中数据的混乱。
怎么使用 cookie?¶
- 语法 document.cookie = “name=value;expires=evalue; path=pvalue; domain=dvalue; secure;”
- 对各个参数的解释
- name=value 必选参数 这是一个键值对,分别表示要存入的 属性 和 值。
cookie 共享¶
cookie 禁用¶
sessionID通过cookie保存在客户端,如果将cookie禁用,必将对session的使用造成一定的影响。
解决这个问题的办法是:URL重写
URL重写
- servlet中涉及向客户端输出页面元素的时候,可以在相应的请求地址外面包上一层方法,也就是说使用response.encodeURL( “请求地址”);为请求地址添加一个JSESSIONID的值
- servlet中涉及跳转到新的页面时,可以使用response.encodeRedirectURL(“请求地址”);为请求地址添加一个JSESSIONID的值
如果 cookie 被禁用,通常会影响某些网站的正常功能。但是,您可以使用以下解决方案之一来处理这种情况:
- 使用
localStorage或sessionStorage替代cookie。 - 使用URL参数来传递数据。例如,您可以使用查询字符串将数据附加到URL中并将其发送到服务器。服务器可以通过查询字符串读取数据并相应地响应。
- 使用HTTP请求头来传递数据。例如,您可以将数据存储在HTTP请求头中,并通过 AJAX 请求将其发送到服务器。服务器可以读取请求头中的数据并响应相应地。
- 使用其它的存储机制,如
IndexedDB或Web SQL等来存储数据。
需要注意的是,这些替代方案都具有各自的优缺点,因此应该根据具体的需求和限制来选择适当地解决方案。例如,一些浏览器可能不支持某些存储机制,或者使用URL参数传递敏感数据可能会存在安全隐患。
Cookie和Session¶
都是用于Web应用中跟踪用户状态的机制,但它们的实现方式和使用方式有所不同。
Cookie是一种在客户端存储信息的机制,它可以在用户的浏览器中存储一些数据,如用户名、购物车信息、用户偏好设置等。当用户访问同一个网站时,网站可以读取这些数据,从而实现对用户状态的跟踪。在Cookie的实现中,数据是以键值对的形式存储在客户端的浏览器中的,并且可以设置过期时间和作用域等属性,以控制Cookie的有效期和范围。
Session是一种在服务器端存储信息的机制,它可以在服务器端存储一些数据,如用户登录状态、购物车信息等。当用户在浏览器中访问同一个Web应用时,服务器可以读取这些数据,从而实现对用户状态的跟踪。在Session的实现中,数据是以键值对的形式存储在服务器端的内存或者磁盘中的,并且可以设置过期时间和作用域等属性,以控制Session的有效期和范围。
总的来说,Cookie和Session都是Web应用中常用的状态跟踪机制,它们的实现方式和使用方式有所不同。在实际开发中,应根据具体的需求和应用场景选择合适的状态跟踪机制,从而保障应用的安全性和可靠性
token 能放在cookie中吗¶
能
- token 是在客户端频繁向服务端请求数据,服务端频繁的去数据库查询用户名和密码并进行对比,判断用户名和密码正确与否,并作出相应提示,在这样的背景下,token 便应运而生。
- 「简单 token 的组成」:uid(用户唯一的身份标识)、time(当前时间的时间戳)、sign(签名,token 的前几位以哈希算法压缩成的一定长度的十六进制字符串)
token认证流程
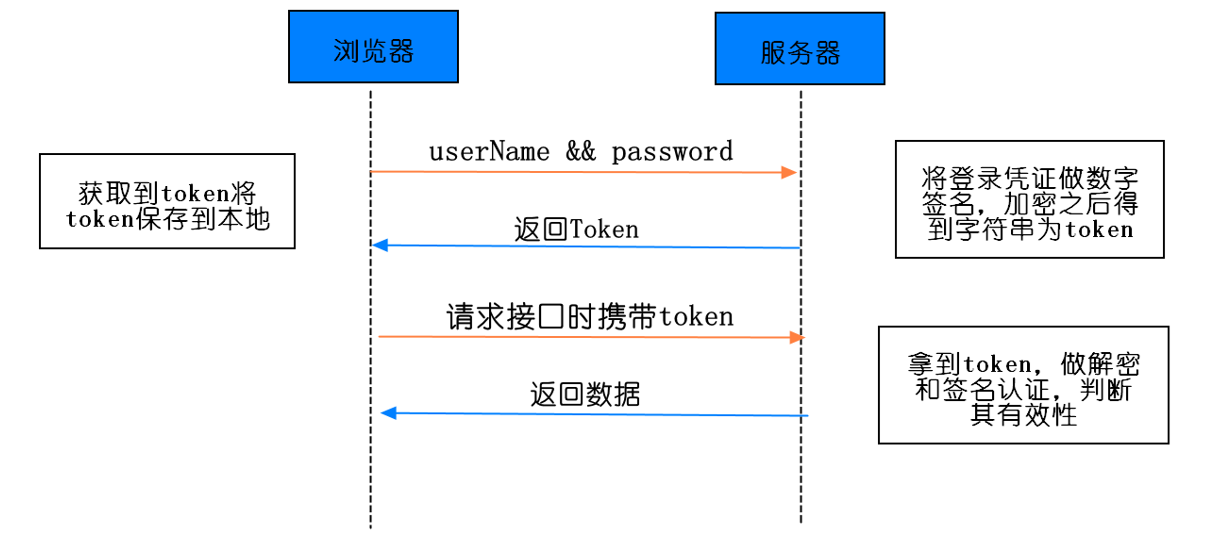
- 客户端使用用户名跟密码请求登录
- 服务端收到请求,去验证用户名与密码
- 验证成功后,服务端签发一个 token ,并把它发送给客户端
- 客户端接收 token 以后会把它存储起来,比如放在 cookie 里或者 localStorage 里
- 客户端每次发送请求时都需要带着服务端签发的 token(把 token 放到 HTTP 的 Header 里)
- 服务端收到请求后,需要验证请求里带有的 token ,如验证成功则返回对应的数据
render¶
浏览器输入URL发生了什么¶
<script>放在<body>尾部,<link>标签放在<head>内部- CSS 不会阻塞 DOM 解析,但是会阻塞 DOM 渲染
- JS 会阻塞 DOM 解析
- CSS 会阻塞 JS 的执行
- JS 会触发页面渲染
分第一次和之后,之后的情况需要考虑缓存的命中
当你用浏览器打开一个链接的时候,计算机做了哪些工作_浏览器打开网址干了什么-CSDN博客
- URL 解析
- 强制缓存命中那么结束
- DNS 查询
- 浏览器缓存
- 操作系统缓存
- 路由器缓存
- ISP缓存
- DNS查询
- 根 DNS 服务器
- 顶级域 DNS 服务器
- 权威 DNS 服务器
- 递归查询或者迭代查询
- ARP请求
- 浏览器查询ARP缓存
- 查看路由表,IP地址是否在路由表里
- 发一个ARP请求
- 封装TCP包,到传输层加入TCP首部,到网络层加入IP首部,到链路层加入以太网首部
- TCP 连接
- 三次握手
- 发送请求,一般是get
- 接受响应,有可能是
304,即协商缓存命中 - 解析页面
- 首先,它将渲染裸露的 HTML 骨架。然后它将检查 HTML 标记并发送 GET 请求以获取网页上的其他元素,例如图像、CSS 样式表、JavaScript 文件等
- 构建DOM树 当解析器发现非阻塞资源,例如一张图片,浏览器会请求这些资源并且继续解析。 当遇到一个 CSS 文件时,解析也可以继续进行, 但是对于
<script>标签(特别是没有async或者defer属性的)会阻塞渲染并停止 HTML 的解析。 尽管浏览器的预加载扫描器加速了这个过程,但过多的脚本仍然是一个重要的瓶颈。 - 预加载扫描器 浏览器构建 DOM 树时,这个过程占用了主线程。当这种情况发生时,预加载扫描仪将解析可用的内容并请求高优先级资源,如 CSS、JavaScript 和 web 字体。 多亏了预加载扫描器,我们不必等到解析器找到对外部资源的引用来请求它。它将在后台检索资源,以便在主 HTML 解析器到达请求的资源时,它们可能已经在运行,或者已经被下载。预加载扫描仪提供的优化减少了阻塞。 等待获取 CSS 不会阻塞 HTML 的解析或者下载,但是它确实会阻塞 JavaScript,因为 JavaScript 经常用于查询元素的 CSS 属性。
- 构建 CSSOM 树
- 优化 CRP 提升页面加载速度需要通过被加载资源的优先级、控制它们加载的顺序和减小这些资源的体积。性能提示包含
- 通过异步、延迟加载或者消除非关键资源来减少关键资源的请求数量
- 优化必须地请求数量和每个请求的文件体积
- 通过区分关键资源的优先级来优化被加载关键资源的顺序,来缩短关键路径长度。
- 渲染页面
- render树
- 布局 第一次确定节点的大小和位置称为布局。随后对节点大小和位置的重新计算称为回流。 在我们的示例中,假设初始布局发生在返回图像之前。由于我们没有声明图像的大小,因此一旦知道图像大小,就会有回流。
- 交互
- 一旦主线程绘制页面完成,你会认为我们已经“准备好了”,但事实并非如此。如果加载包含 JavaScript(并且延迟到
onload事件激发后执行),则主线程可能很忙,无法用于滚动、触摸和其他交互。 在我们的示例中,可能图像加载很快,但anotherscript.js文件可能是 2MB,而且用户的网络连接很慢。在这种情况下,用户可以非常快地看到页面,但是在下载、解析和执行脚本之前,就无法滚动。这不是一个好的用户体验。避免占用主线程,如下面的网页测试示例所示:
- 一旦主线程绘制页面完成,你会认为我们已经“准备好了”,但事实并非如此。如果加载包含 JavaScript(并且延迟到
浏览器渲染页面¶
- HTML 被 HTML 解析器解析成 DOM 树;
- CSS 被 CSS 解析器解析成 CSSOM 树;
- 结合 DOM 树和 CSSOM 树,生成一棵渲染树(Render Tree),这一过程称为 Attachment;
- 生成布局(flow),浏览器在屏幕上“画”出渲染树中的所有节点;
- 将布局绘制(paint)在屏幕上,显示出整个页面。
不同的浏览器内核不同,所以渲染过程不太一样。
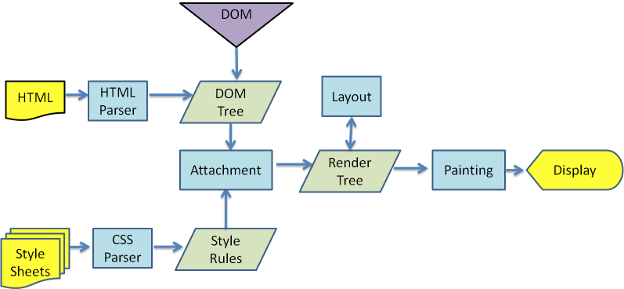
WebKit 主流程
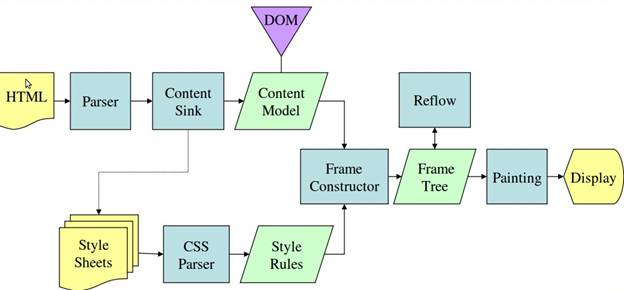
Mozilla 的 Gecko 呈现引擎主流程
由上面两张图可以看出,虽然主流浏览器渲染过程叫法有区别,但是主要流程还是相同的。 Gecko 将视觉格式化元素组成的树称为“框架树”。每个元素都是一个框架。WebKit 使用的术语是“呈现树”,它 由“呈现对象”组成。对于元素的放置,WebKit 使用的术语是“布局”,而 Gecko 称之为“重排”。对于连接 DOM 节点和可视化信息从而创建呈现树的过程,WebKit 使用的术语是“附加”。
重绘、重排区别如何避免¶
- 重排(Reflow):当渲染树的一部分必须更新并且节点的尺寸发生了变化,浏览器会使渲染树中受到影响的部分失效,并重新构造渲染树。
- 重绘(Repaint):是在一个元素的外观被改变所触发的浏览器行为,浏览器会根据元素的新属性重新绘制,使元素呈现新的外观。比如改变某个元素的背景色、文字颜色、边框颜色等等
- 区别:重绘不一定需要重排(比如颜色的改变),重排必然导致重绘(比如改变网页位置)
- 引发重排
- 添加、删除可见的dom
- 元素的位置改变
- 元素的尺寸改变(外边距、内边距、边框厚度、宽高、等几何属性)
- 页面渲染初始化
- 浏览器窗口尺寸改变
- 获取某些属性。当获取一些属性时,浏览器为取得正确的值也会触发重排,它会导致队列刷新,这些属性包括:offsetTop、offsetLeft、 offsetWidth、offsetHeight、scrollTop、scrollLeft、scrollWidth、scrollHeight、clientTop、clientLeft、clientWidth、clientHeight、getComputedStyle() ( currentStyle in IE)。所以,在多次使用这些值时应进行缓存。
-
优化:
浏览器自己的优化:
浏览器会维护1个队列,把所有会引起重排、重绘的操作放入这个队列,等队列中的操作到一定数量或者到了一定时间间隔,浏览器就会flush队列,进行一批处理,这样多次重排,重绘变成一次重排重绘
减少 reflow/repaint:
- 不要一条一条地修改 DOM 的样式。可以先定义好 css 的 class,然后修改 DOM 的 className。
- 不要把 DOM 结点的属性值放在一个循环里当成循环里的变量。
- 为动画的 HTML 元件使用 fixed 或 absolute 的 position,那么修改他们的 CSS 是不会 reflow 的。
- 千万不要使用 table 布局。因为可能很小的一个小改动会造成整个 table 的重新布局。( table及其内部元素除外,它可能需要多次计算才能确定好其在渲染树中节点的属性,通常要花3倍于同等元素的时间。这也是为什么我们要避免使用table做布局的一个原因。)
- 不要在布局信息改变的时候做查询(会导致渲染队列强制刷新)
内存管理¶
浏览器垃圾回收机制¶
浏览器的 Javascript 具有自动垃圾回收机制(GC:Garbage Collecation),也就是说,执行环境会负责管理代码执行过程中使用的内存。其原理是: 垃圾收集器会定期(周期性)找出那些不在继续使用的变量,然后释放其内存。但是这个过程不是实时的,因为其开销比较大并且GC时停止响应其他操作,所以垃圾回收器会按照固定的时间间隔周期性的执行。
不再使用的变量也就是生命周期结束的变量,当然只可能是局部变量,全局变量的生命周期直至浏览器卸载页面才会结束。局部变量只在函数的执行过程中存在,而在这个过程中会为局部变量在栈或堆上分配相应的空间,以存储它们的值,然后在函数中使用这些变量,直至函数结束,而闭包中由于内部函数的原因,外部函数并不能算是结束。
还是上代码说明吧:
function fn1() { var obj = {name: 'hanzichi', age: 10};}function fn2() { var obj = {name: 'hanzichi', age: 10}; return obj;}var a = fn1();var b = fn2();
我们来看代码是如何执行的。首先定义了两个function,分别叫做fn1和fn2,当fn1被调用时,进入fn1的环境,会开辟一块内存存放对象{name: ‘hanzichi’, age: 10},而当调用结束后,出了fn1的环境,那么该块内存会被js引擎中的垃圾回收器自动释放;在fn2被调用的过程中,返回的对象被全局变量b所指向,所以该块内存并不会被释放。
这里问题就出现了:到底哪个变量是没有用的?所以垃圾收集器必须跟踪到底哪个变量没用,对于不再有用的变量打上标记,以备将来收回其内存。用于标记的无用变量的策略可能因实现而有所区别,通常情况下有两种实现方式: 标记清除**和**引用计数。引用计数不太常用,标记清除较为常用。
2. 标记清除¶
js中最常用的垃圾回收方式就是标记清除。当变量进入环境时,例如,在函数中声明一个变量,就将这个变量标记为“进入环境”。从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到它们。而当变量离开环境时,则将其标记为“离开环境”。
垃圾回收器在运行的时候会给存储在内存中的所有变量都加上标记(当然,可以使用任何标记方式)。然后,它会去掉环境中的变量以及被环境中的变量引用的变量的标记(闭包)。而在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。最后,垃圾回收器完成内存清除工作,销毁那些带标记的值并回收它们所占用的内存空间。 到目前为止,IE9+、Firefox、Opera、Chrome、Safari的js实现使用的都是标记清除的垃圾回收策略或类似的策略,只不过垃圾收集的时间间隔互不相同。
3. 引用计数¶
引用计数的含义是跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型值赋给该变量时,则这个值的引用次数就是1。如果同一个值又被赋给另一个变量,则该值的引用次数加1。相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数减1。当这个值的引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其占用的内存空间回收回来。这样,当垃圾回收器下次再运行时,它就会释放那些引用次数为0的值所占用的内存。
function test() { var a = {}; //a的引用次数为0 var b = a; //a的引用次数加1,为1 var c = a; //a的引用次数再加1,为2 var b = {}; //a的引用次数减1,为1}
Netscape Navigator3是最早使用引用计数策略的浏览器,但很快它就遇到一个严重的问题:循环引用。循环引用指的是对象A中包含一个指向对象B的指针,而对象B中也包含一个指向对象A的引用。
以上代码a和b的引用次数都是2,fn() 执行完毕后,两个对象都已经离开环境,在标记清除方式下是没有问题的,但是在引用计数策略下,因为a和b的引用次数不为0,所以不会被垃圾回收器回收内存,如果fn函数被大量调用,就会造成内存泄露。在IE7与IE8上,内存直线上升。
我们知道,IE中有一部分对象并不是原生js对象。例如,其内存泄露DOM和BOM中的对象就是使用C++以COM对象的形式实现的,而COM对象的垃圾回收机制采用的就是引用计数策略。因此,即使IE的js引擎采用标记清除策略来实现,但js访问的 **COM对象依然是基于引用计数策略**的。换句话说,只要在IE中涉及COM对象,就会存在循环引用的问题。
var element = document.getElementById("some_element");var myObject = new Object();myObject.e = element;element.o = myObject;
这个例子在一个DOM元素(element)与一个原生js对象(myObject) 之间创建了循环引用。其中,变量myObject有一个属性e指向element对象;而变量element也有一个属性o回指myObject。由于存在这个循环引用,即使例子中的DOM从页面中移除,它也永远不会被回收。
举个栗子:
window.onload = function outerFunction() { var obj = document.getElementById("element"); obj.onclick = function innerFunction() { };};
这段代码看起来没什么问题,但是obj引用了document.getElementById(‘element’),而document.getElementById(‘element’) 的onclick方法会引用外部环境中的变量,自然也包括obj,是不是很隐蔽啊。( 在比较新的浏览器中在移除Node的时候已经会移除其上的event了,但是在老的浏览器,特别是ie上会有这个bug)
解决办法:
最简单的方式就是自己手工解除循环引用,比如刚才的函数可以这样
myObject.element = null;element.o = null;window.onload = function outerFunction() { var obj = document.getElementById("element"); obj.onclick = function innerFunction() { }; obj = null;};
将变量设置为null意味着切断变量与它此前引用的值之间的连接。当垃圾回收器下次运行时,就会删除这些值并回收它们占用的内存。
要注意的是,IE9+并不存在循环引用导致Dom内存泄露问题,可能是微软做了优化,或者Dom的回收方式已经改变
什么时候触发垃圾回收?¶
垃圾回收器周期性运行,如果分配的内存非常多,那么回收工作也会很艰巨,确定垃圾回收时间间隔就变成了一个值得思考的问题。IE6的垃圾回收是根据内存分配量运行的,当环境中存在256个变量、4096个对象、64k的字符串任意一种情况的时候就会触发垃圾回收器工作,看起来很科学,不用按一段时间就调用一次,有时候会没必要,这样按需调用不是很好吗?但是如果环境中就是有这么多变量等一直存在,现在脚本如此复杂,很正常,那么结果就是垃圾回收器一直在工作,这样浏览器就没法儿玩儿了。
微软在IE7中做了调整,触发条件不再是固定的,而是动态修改的,初始值和IE6相同,如果垃圾回收器回收的内存分配量低于程序占用内存的15%,说明大部分内存不可被回收,设的垃圾回收触发条件过于敏感,这时候把临街条件翻倍,如果回收的内存高于85%,说明大部分内存早就该清理了,这时候把触发条件置回。这样就使垃圾回收工作职能了很多
4.2 合理的GC方案¶
1. 基础方案¶
Javascript引擎基础GC方案是(simple GC):mark and sweep(标记清除),即:
- 遍历所有可访问的对象。
- 回收已不可访问的对象。
2. GC的缺陷¶
和其他语言一样,javascript的GC策略也无法避免一个问题:GC时,停止响应其他操作,这是为了安全考虑。而Javascript的GC在100ms甚至以上,对一般的应用还好,但对于JS游戏,动画对连贯性要求比较高的应用,就麻烦了。这就是新引擎需要优化的点:避免GC造成的长时间停止响应。
3. GC优化策略¶
David大叔主要介绍了2个优化方案,而这也是最主要的2个优化方案了:
-
分代回收(Generation GC) 这个和Java回收策略思想是一致的,也是V8所主要采用的。目的是通过区分“临时”与“持久”对象;多回收“临时对象”区(young generation),少回收“持久对象”区(tenured generation),减少每次需遍历的对象,从而减少每次GC的耗时。如图:
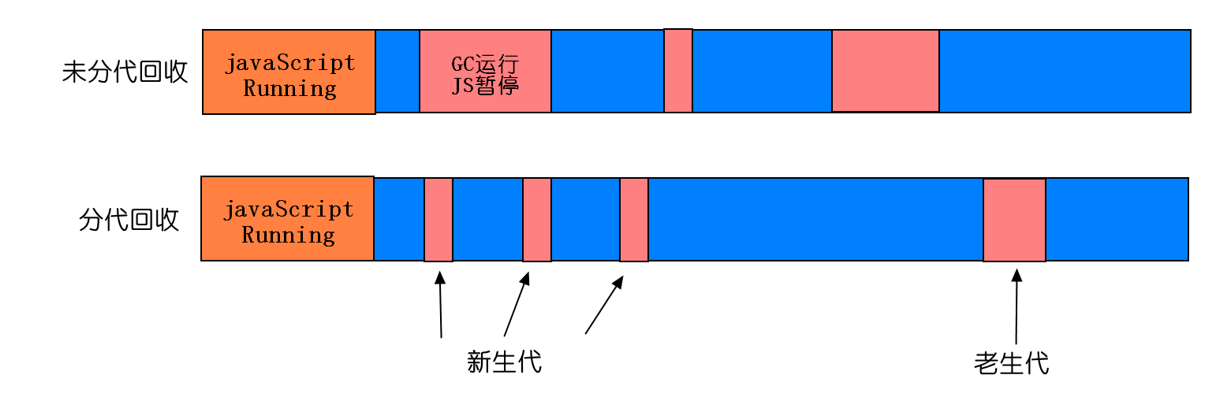
这里需要补充的是:对于tenured generation对象,有额外的开销:把它从young generation迁移到tenured generation,另外,如果被引用了,那引用的指向也需要修改。
-
增量GC 这个方案的思想很简单,就是“每次处理一点,下次再处理一点,如此类推”。如图:
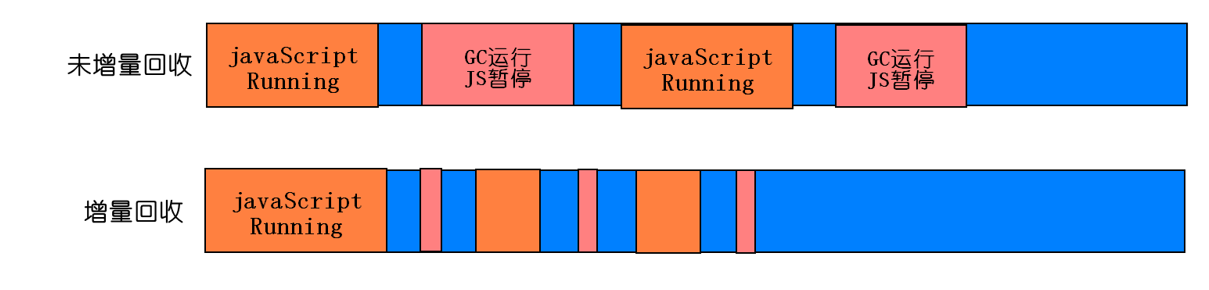
这种方案,虽然耗时短,但中断较多,带来了上下文切换频繁的问题。
因为每种方案都其适用场景和缺点,因此在实际应用中,会根据实际情况选择方案。
比如:低 (对象/s) 比率时,中断执行GC的频率,simple GC更低些;如果大量对象都是长期“存活”,则分代处理优势也不大。
Other¶
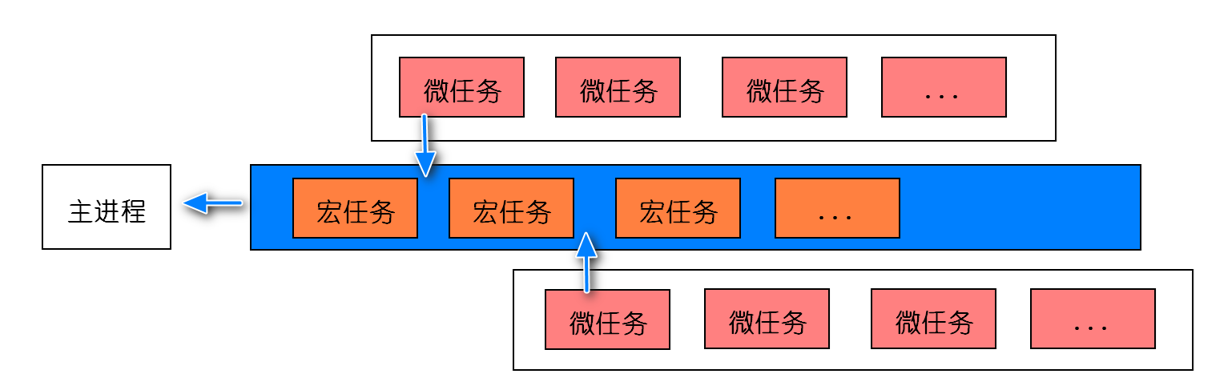
Event loop¶
主线程从“任务队列”中读取执行事件,这个过程是循环不断的,这个机制被称为事件循环。此机制具体如下: 主线程会不断从任务队列中按顺序取任务执行,每执行完一个任务都会检查microtask队列是否为空(执行完一个 任务的具体标志是函数执行栈为空),如果不为空则会一次性执行完所有microtask。然后再进入下一个循环去任务队列中取下一个任务执行。
详细步骤:
- 选择当前要执行的宏任务队列,选择一个最先进入任务队列的宏任务,如果没有宏任务可以选择,则会跳转至microtask的执行步骤。
- 将事件循环的当前运行宏任务设置为已选择的宏任务。
- 运行宏任务。
- 将事件循环的当前运行任务设置为null。
- 将运行完的宏任务从宏任务队列中移除。
- microtasks步骤:进入microtask检查点。
- 更新界面渲染。
- 返回第一步。
执行进入microtask检查的的具体步骤如下:
- 设置进入microtask检查点的标志为true。
- 当事件循环的微任务队列不为空时:选择一个最先进入microtask队列的microtask;设置事件循环的当前运行任务为已选择的microtask;运行microtask;设置事件循环的当前运行任务为null;将运行结束 的microtask从microtask队列中移除。
- 对于相应事件循环的每个环境设置对象(environment settings object),通知它们哪些promise为 rejected。
- 清理indexedDB的事务。
- 设置进入microtask检查点的标志为false。
需要注意的是:当前执行栈执行完毕时会立刻先处理所有微任务队列中的事件, 然后再去宏任务队列中取出一个 事件。同一次事件循环中, 微任务永远在宏任务之前执行。