Web Scenario¶
登录¶
几种常用的登录方式。
Cookie + Session 登录¶
HTTP 是一种无状态的协议,客户端每次发送请求时,首先要和服务器端建立一个连接,在请求完成后又会断开这个连接。这种方式可以节省传输时占用的连接资源,但同时也存在一个问题:每次请求都是独立的,服务器端无法判断本次请求和上一次请求是否来自同一个用户,进而也就无法判断用户的登录状态。
为了解决 HTTP 无状态的问题,Lou Montulli 在 1994 年的时候,推出了 Cookie。
Cookie 是服务器端发送给客户端的一段特殊信息,这些信息以文本的方式存放在客户端,客户端每次向服务器端发送请求时都会带上这些特殊信息。
有了 Cookie 之后,服务器端就能够获取到客户端传递过来的信息了,如果需要对信息进行验证,还需要通过 Session。
客户端请求服务端,服务端会为这次请求开辟一块内存空间,这个便是 Session 对象。
有了 Cookie 和 Session 之后,我们就可以进行登录认证了。
Cookie + Session 实现流程
Cookie + Session 的登录方式是最经典的一种登录方式,现在仍然有大量的企业在使用。

img
- 用户访问a.com/pageA,并输入密码登录。
- 服务器验证密码无误后,会创建 SessionId,并将它保存起来。
- 服务器端响应这个 HTTP 请求,并通过 Set-Cookie 头信息,将 SessionId 写入 Cookie 中。
服务器端的 SessionId 可能存放在很多地方,例如:内存、文件、数据库等。
第一次登录完成之后,后续的访问就可以直接使用 Cookie 进行身份验证了:

img
- 用户访问a.com/pageB页面时,会自动带上第一次登录时写入的 Cookie。
- 服务器端比对 Cookie 中的 SessionId 和保存在服务器端的 SessionId 是否一致。
- 如果一致,则身份验证成功。
Cookie + Session 存在的问题
虽然我们使用 Cookie + Session 的方式完成了登录验证,但仍然存在一些问题:
- 由于服务器端需要对接大量的客户端,也就需要存放大量的 SessionId,这样会导致服务器压力过大。
- 如果服务器端是一个集群,为了同步登录态,需要将 SessionId 同步到每一台机器上,无形中增加了服务器端维护成本。
- 由于 SessionId 存放在 Cookie 中,所以无法避免 CSRF 攻击。
Token 登录¶
为了解决 Session + Cookie 机制暴露出的诸多问题,我们可以使用 Token 的登录方式。
Token 是服务端生成的一串字符串,以作为客户端请求的一个令牌。当第一次登录后,服务器会生成一个 Token 并返回给客户端,客户端后续访问时,只需带上这个 Token 即可完成身份认证。
Token 机制实现流程
用户首次登录时:

img
- 用户输入账号密码,并点击登录。
- 服务器端验证账号密码无误,创建 Token。
- 服务器端将 Token 返回给客户端,由*客户端自由保存***。
后续页面访问时:

img
- 用户访问a.com/pageB时,带上第一次登录时获取的 Token。
- 服务器端验证 Token ,有效则身份验证成功。
Token 机制的特点
根据上面的案例,我们可以分析出 Token 的优缺点:
- 服务器端不需要存放 Token,所以不会对服务器端造成压力,即使是服务器集群,也不需要增加维护成本。
- Token 可以存放在前端任何地方,可以不用保存在 Cookie 中,提升了页面的安全性。
- Token 下发之后,只要在生效时间之内,就一直有效,如果服务器端想收回此 Token 的权限,并不容易。
Token 的生成方式
最常见的 Token 生成方式是使用 JWT(Json Web Token),它是一种简洁的,自包含的方法用于通信双方之间以 JSON 对象的形式安全的传递信息。
上文中我们说到,使用 Token 后,服务器端并不会存储 Token,那怎么判断客户端发过来的 Token 是合法有效的呢?
答案其实就在 Token 字符串中,其实 Token 并不是一串杂乱无章的字符串,而是通过多种算法拼接组合而成的字符串,我们来具体分析一下。
JWT 算法主要分为 3 个部分:header(头信息),playload(消息体),signature(签名)。
header 部分指定了该 JWT 使用的签名算法:
playload 部分表明了 JWT 的意图:
signature 部分为 JWT 的签名,主要为了让 JWT 不能被随意篡改,签名的方法分为两个步骤:
- 输入base64url编码的 header 部分、base64url编码的 playload 部分,输出 unsignedToken。
- 输入服务器端私钥、unsignedToken,输出 signature 签名。
const base64Header = encodeBase64(header)const base64Payload = encodeBase64(payload)const unsignedToken = `${base64Header}.${base64Payload}`const key = '服务器私钥'signature = HMAC(key, unsignedToken)
最后的 Token 计算如下:
const base64Header = encodeBase64(header)const base64Payload = encodeBase64(payload)const base64Signature = encodeBase64(signature)token = `${base64Header}.${base64Payload}.${base64Signature}`
服务器在判断 Token 时:
const [base64Header, base64Payload, base64Signature] = token.split('.')const signature1 = decodeBase64(base64Signature)const unsignedToken = `${base64Header}.${base64Payload}`const signature2 = HMAC('服务器私钥', unsignedToken)if (signature1 === signature2) { return '签名验证成功,token 没有被篡改'}const payload = decodeBase64(base64Payload)if (new Date() - payload.iat < 'token 有效期') { return 'token 有效'}
有了 Token 之后,登录方式已经变得非常高效,接下来我们介绍另外两种登录方式。
SSO 单点登录¶
https://github.com/febobo/web-interview/issues/91
单点登录指的是在公司内部搭建一个公共的认证中心,公司下的所有产品的登录都可以在认证中心里完成,一个产品在认证中心登录后,再去访问另一个产品,可以不用再次登录,即可获取登录状态。
登录机制¶
用户首次访问时,需要在认证中心登录:
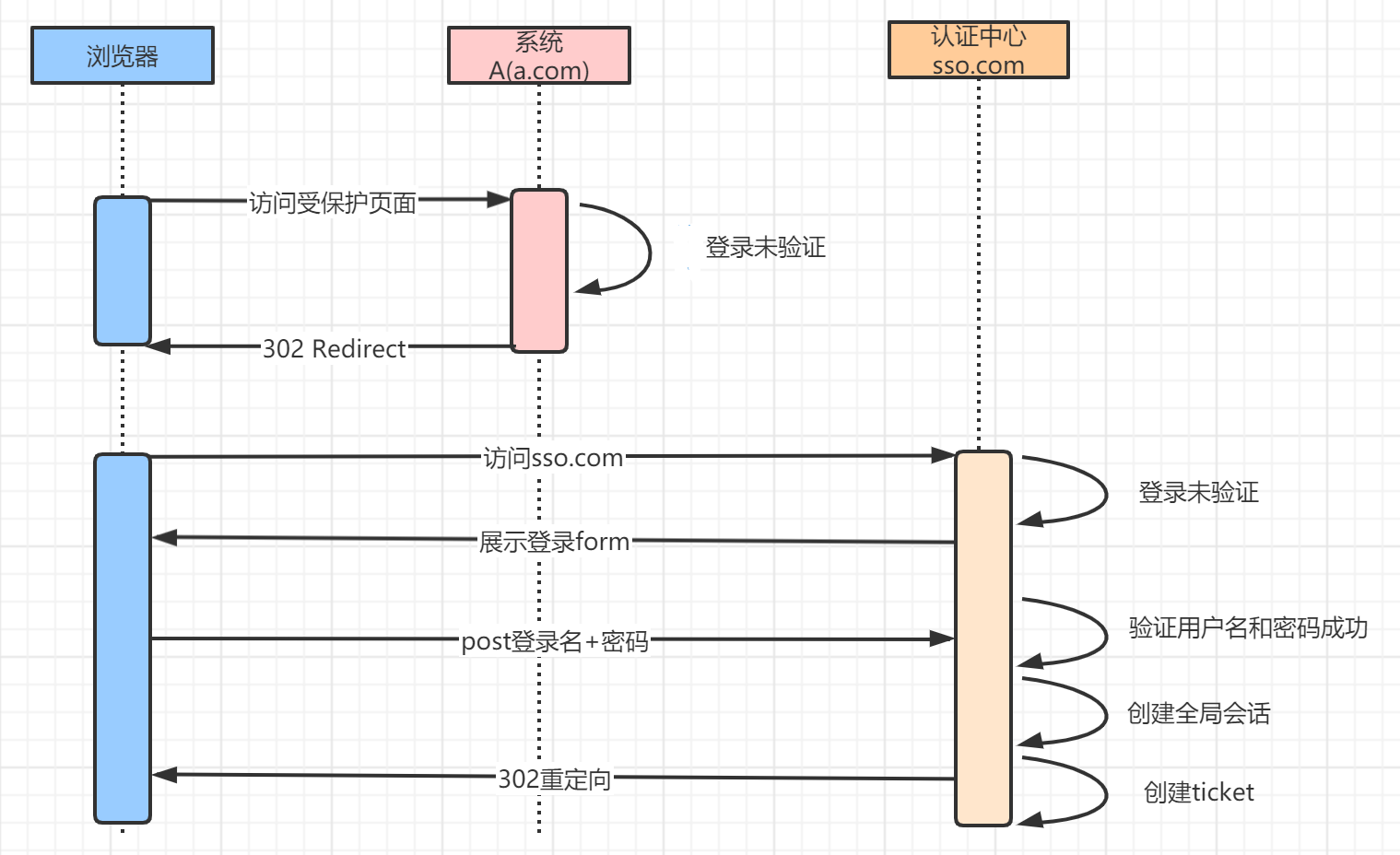
- 用户访问网站
a.com下的pageA页面。 - 由于没有登录,则会重定向到认证中心,并带上回调地址
www.sso.com?return_uri=a.com/pageA,以便登录后直接进入对应页面。 - 用户在认证中心输入账号密码,提交登录。
- 认证中心验证账号密码有效,然后重定向
a.com?ticket=123带上授权码ticket,并将认证中心sso.com的登录态写入Cookie。 - 在
a.com服务器中,拿着ticket向认证中心确认,授权码ticket真实有效。 - 验证成功后,服务器将登录信息写入
Cookie(此时客户端有 2 个Cookie分别存有a.com和sso.com的登录态)。
认证中心登录完成之后,继续访问a.com下的其他页面:
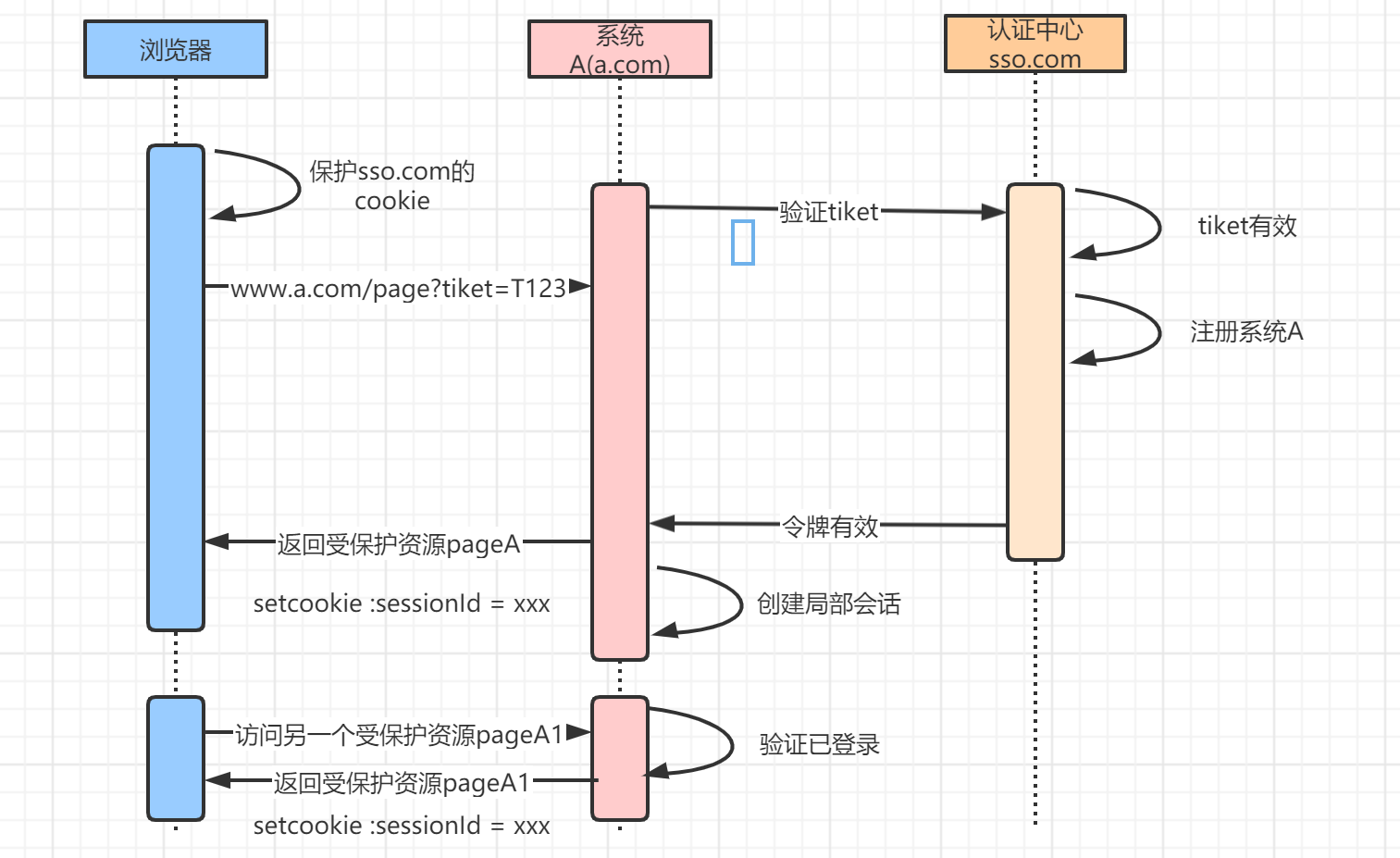
这个时候,由于a.com存在已登录的 Cookie 信息,所以服务器端直接认证成功。
如果认证中心登录完成之后,访问b.com下的页面:
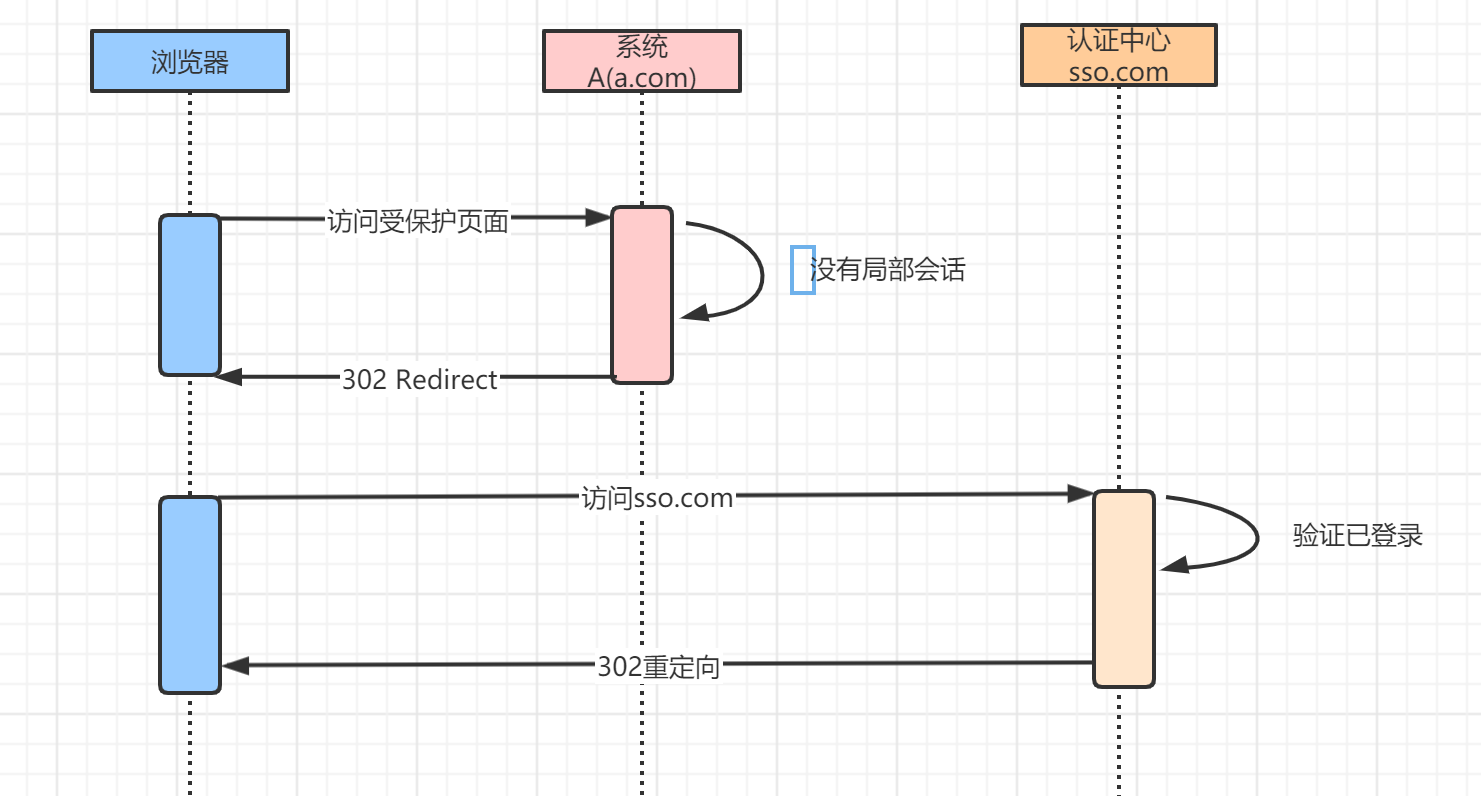
这个时候,由于认证中心存在之前登录过的 Cookie,所以也不用再次输入账号密码,直接返回第 4 步,下发 ticket 给b.com即可。
SSO 单点登录退出¶
目前我们已经完成了单点登录,在同一套认证中心的管理下,多个产品可以共享登录态。现在我们需要考虑退出了,即:在一个产品中退出了登录,怎么让其他的产品也都退出登录?
原理其实不难,可以回过头来看第 5 步,每一个产品在向认证中心验证 ticket 时,其实可以顺带将自己的退出登录 api 发送到认证中心。
当某个产品c.com退出登录时:
- 清空c.com中的登录态 Cookie。
- 请求认证中心sso.com中的退出 api。
- 认证中心遍历下发过 ticket 的所有产品,并调用对应的退出 api,完成退出。
OAuth 第三方登录¶
在上文中,我们使用单点登录完成了多产品的登录态共享,但都是建立在一套统一的认证中心下,对于一些小型企业,未免太麻烦,有没有一种登录能够做到开箱即用?
OAuth 机制实现流程
这里以微信开放平台的接入流程为例:
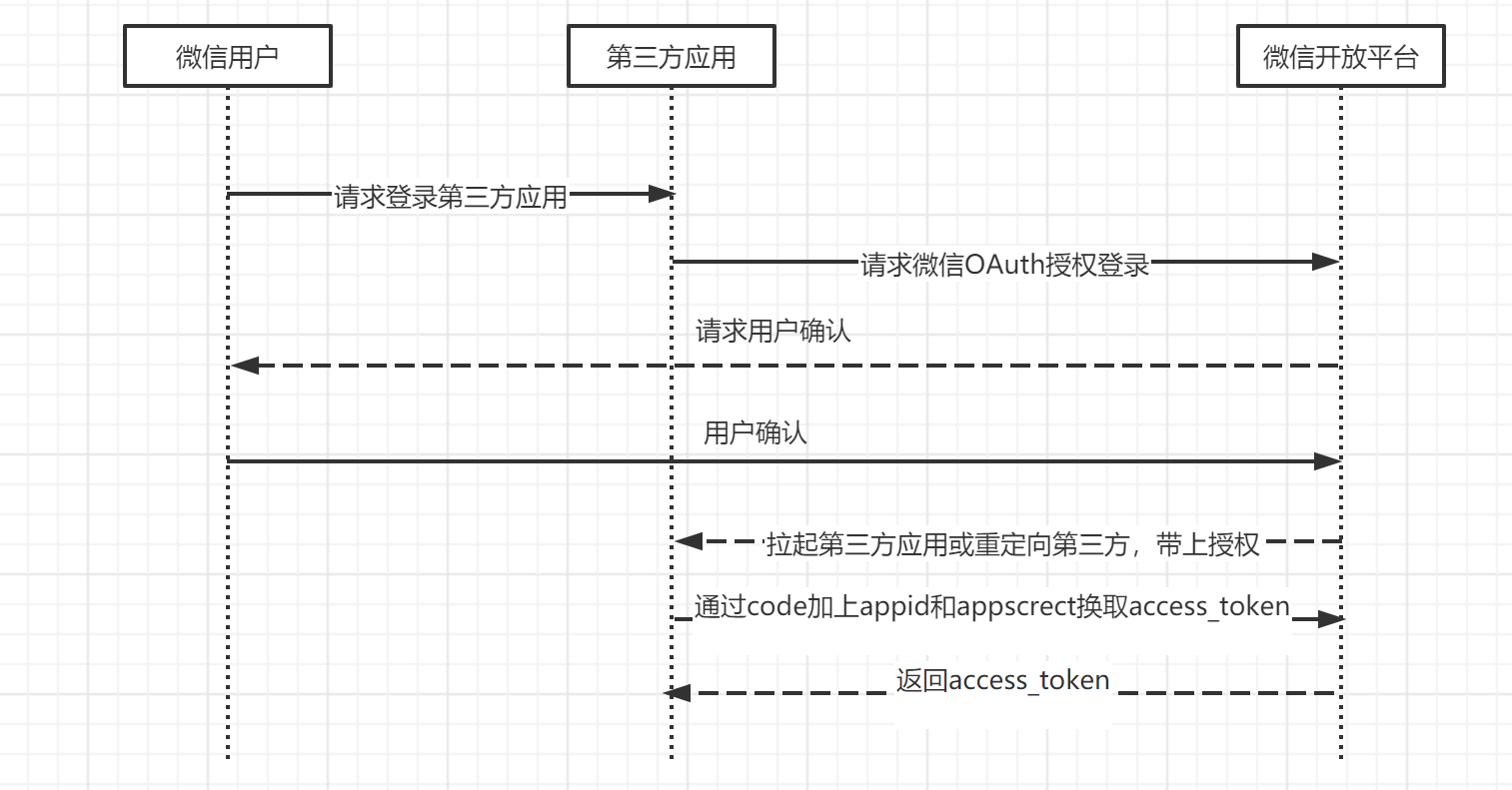
- 首先,a.com的运营者需要在微信开放平台注册账号,并向微信申请使用微信登录功能。
- 申请成功后,得到申请的 appid、appsecret。
- 用户在a.com上选择使用微信登录。
- 这时会跳转微信的 OAuth 授权登录,并带上a.com的回调地址。
- 用户输入微信账号和密码,登录成功后,需要选择具体的授权范围,如:授权用户的头像、昵称等。
- 授权之后,微信会根据拉起a.com?code=123,这时带上了一个临时票据 code。
- 获取 code 之后,a.com会拿着 code 、appid、appsecret,向微信服务器申请 token,验证成功后,微信会下发一个 token。
- 有了 token 之后,a.com就可以凭借 token 拿到对应的微信用户头像,用户昵称等信息了。
- a.com提示用户登录成功,并将登录状态写入 Cooke,以作为后续访问的凭证。
总结¶
本文介绍了 4 种常见的登录方式,原理应该大家都清楚了,总结一下这 4 种方案的使用场景:
- Cookie + Session 历史悠久,适合于简单的后端架构,需开发人员自己处理好安全问题。
- Token 方案对后端压力小,适合大型分布式的后端架构,但已分发出去的 token ,如果想收回权限,就不是很方便了。
- SSO 单点登录,适用于中大型企业,想要统一内部所有产品的登录方式。
- OAuth 第三方登录,简单易用,对用户和开发者都友好,但第三方平台很多,需要选择合适自己的第三方登录平台。
懒加载¶
什么是懒加载?
懒加载是一种在页面加载时延迟加载一些非关键资源的技术,换句话说就是按需加载。对于图片来说,非关键通常意味着离屏。 我们之前看到的懒加载一般是这样的形式:
- 浏览一个网页,准备往下拖动滚动条
- 拖动一个占位图片到视窗
- 占位图片被瞬间替换成最终的图片
网页首先用一张轻量级的图片占位,当占位图片被拖动到视窗,瞬间加载目标图片,然后替换占位图片。
为什么要懒加载而不直接加载?
- 浪费流量。在不计流量收费的网络,这可能不重要;在按流量收费的网络中,毫无疑问,一次性加载大量图片就是在浪费用户的钱。
- 消耗额外的电量和其他的系统资源,并且延长了浏览器解析的时间。因为媒体资源在被下载完成后,浏览器必须对它进行解码,然后渲染在视窗上,这些操作都需要一定的时间。
懒加载图片和视频,可以减少页面加载的时间、页面的大小和降低系统资源的占用,这些对于性能都有显著地提升。
图片压缩算法¶
参考答案:
- PNG图片的压缩,分两个阶段:
- 预解析(Prediction):这个阶段就是对png图片进行一个预处理,处理后让它更方便后续的压缩。说白了,就是一个女神,在化妆前,会先打底,先涂乳液和精华,方便后续上妆、美白、眼影、打光等等。
- 压缩(Compression):执行Deflate压缩,该算法结合了 LZ77 算法和 Huffman 算法对图片进行编码。
预解析(Prediction)
png图片用差分编码(Delta encoding)对图片进行预处理,处理每一个的像素点中每条通道的值,差分编码主要有几种:
- 不过滤
- X-A
- X-B
- X-(A+B)/2(又称平均值)
- Paeth推断(这种比较复杂)
加载很多图片时的优化方法,页面加载时的交互优化¶
- 图片压缩
- 页面是由“小图”平铺来的,却需要加载大量原图,得不偿失。于是很自然的会想到,将“小图”变为真正的小图,当实际点击大图时再去请求原图,这样便会大大减少页面加载时间。
- 将图片转Base64格式来节约请求 当我们的一个页面中要传入很多图片时,特别是一些比较小的图片,十几K、几K,这些小图标都会增加HTTP请求。比如要下载一些一两K大的小图标,其实请求时带上的额外信息有可能比图标的大小还要大。所以,在请求越多时,在网络传输的数据自然就越多了,传输的数据自然也就变慢了。而这里,我们采用Base64的编码方式将图片直接嵌入到网页中,而不是从外部载入,这样就减少了HTTP请求。
- 图片预加载 图片预加载的主要思路就是把稍后需要用到的图片悄悄的提前加载到本地,因为浏览器有缓存的原因,如果稍后用到这个url的图片了,浏览器会优先从本地缓存找该url对应的图片,如果图片没过期的话,就使用这个图片其中图片预加载也分为三种,无序加载,有序加载,基于用户行为的预加载(点击某个按钮或者滚动的时候进行加载)。 预加载的实现很简单,其核心说到底就两句话:
- 其他常见优化
- 将图片服务和应用服务分离 对于服务器来说,图片是比较消耗系统资源的,如果将图片服务和应用服务放在同一服务器的话,应用服务器很容易会因为图片的高I/O负载而崩溃,所以当网站存在大量的图片读写操作时,建议使用图片服务器。
- 图片懒加载 页面加载后只让文档可视区内的图片显示,其它不显示,随着用户对页面的滚动,判断其区域位置,生成img标签,让到可视区的图片加载出来。jQuery的lazyload插件便是一个可以实现图片延迟加载的插件,在用户触发某个条件之后再加载对应的图片资源,这对网页的打开速度有很大提升。 引入lazyload.js,对我们想要延迟加载的图片添加lazy样式,用”data-original” 替换图片的引用路径
关于样式规范统一化的实现¶
页面跳转的方式¶
怎么监听内容的改变:监听oninput¶
如何触发下拉刷新、上拉加载¶
扫描二维码登录的原理¶
页面资源预加载¶
前端切换中英文¶
方法1:(中英文各做一份,然后用不同的文件夹区分开来,点击切换语言时,链接跳转到不同文件夹就行了)
优点:各自的版本是分离开来的,比较稳定,不会出现互相干扰(共用数据库资料的除外)
缺点:修改一个样式或功能,要把变更的操作(代码逻辑、更换图片、修改样式等)在所有的语言版 本上重复一次,加重了工作量
场景:个人认为符合下面2种场景可以考虑使用这种方法
注: 如果切换的语言版本很少,并且本身网站不复杂(比如电商网站不推荐)
整体内容相对固定,布局比较简洁,扁平化,改动不会太频繁的(比如新闻类网站不推荐)
方法2:借助 jquery 插件——jquery.i18n.properties
方法3:使用微软字典整站翻译
1000 万 个ip,如何做到O(1) 查找¶
用户体验优化¶
数据展示优化¶
- 减少 HTTP 请求
- 使用 HTTP2:解析速度快、多路复用、首部压缩、优先级高、可以对不同的流的流量进行精确控制、服务器可以对一个客户端请求发送多个响应
- 使用服务端渲染:首屏渲染快,SEO 好
- 静态资源使用 CDN:在多个位置部署服务器,让用户离服务器更近,从而缩短请求时间
- 将 CSS 放在文件头部,JavaScript 文件放在底部:所有放在 head 标签里的 CSS 和 JS 文件都会堵塞渲染。如果这些 CSS 和 JS 需要加载和解析很久的话,那么页面就空白了。所以 JS 文件要放在底部,等 HTML 解析完了再加载 JS 文件
- 使用字体图标 iconfont 代替图片图标:不会失真,生成的文件特别小。
- 善用缓存,不重复加载相同的资源:为了避免用户每次访问网站都得请求文件,我们可以通过添加 Expires 或 max-age 来控制这一行为。Expires 设置了一个时间,只要在这个时间之前,浏览器都不会请求文件,而是直接使用缓存。而 max-age 是一个相对时间,建议使用 max-age 代替 Expires 。
- 压缩文件:压缩文件可以减少文件下载时间
- 图片优化:
- 图片延迟加载
- 响应式图片
- 调整图片大小
- 降低图片质量
- 尽可能利用 CSS3 效果代替图片
- 使用 webp 格式的图片
- 通过 webpack 按需加载代码,提取第三库代码,减少 ES6 转为 ES5 的冗余代码
- 减少重绘重排